GlobalFlags or ScopedTrainFlags callback. Learn more about these callbacks in Performance Flags
We have two guides depending on your familiarity with microbatching. We recommend reading the rest of this guide before moving on to the beginner or advanced guides:
- Beginner Guide: Covers how to set Global Batch Size (GBS) and how to use training modes.
- Advanced Guide: Covers how the platform picks or overrides Micro Batch Size (MBS) and how to optimize it manually.
How It Works
Microbatching divides large training batches into smaller portions, allowing models to process batch sizes that exceed available device memory. The Cerebras software stack facilitates automatic microbatching for transformer models without requiring any modifications to the model code. Additionally, the software can automatically determine optimal microbatch sizes. As illustrated in the figure below, when a batch exceeds memory limits it’s segmented into manageable microbatches that are processed sequentially. The system accumulates gradients across these microbatches before updating network weights, effectively simulating training with the full batch size. Statistics like loss can be combined across microbatches in a similar way.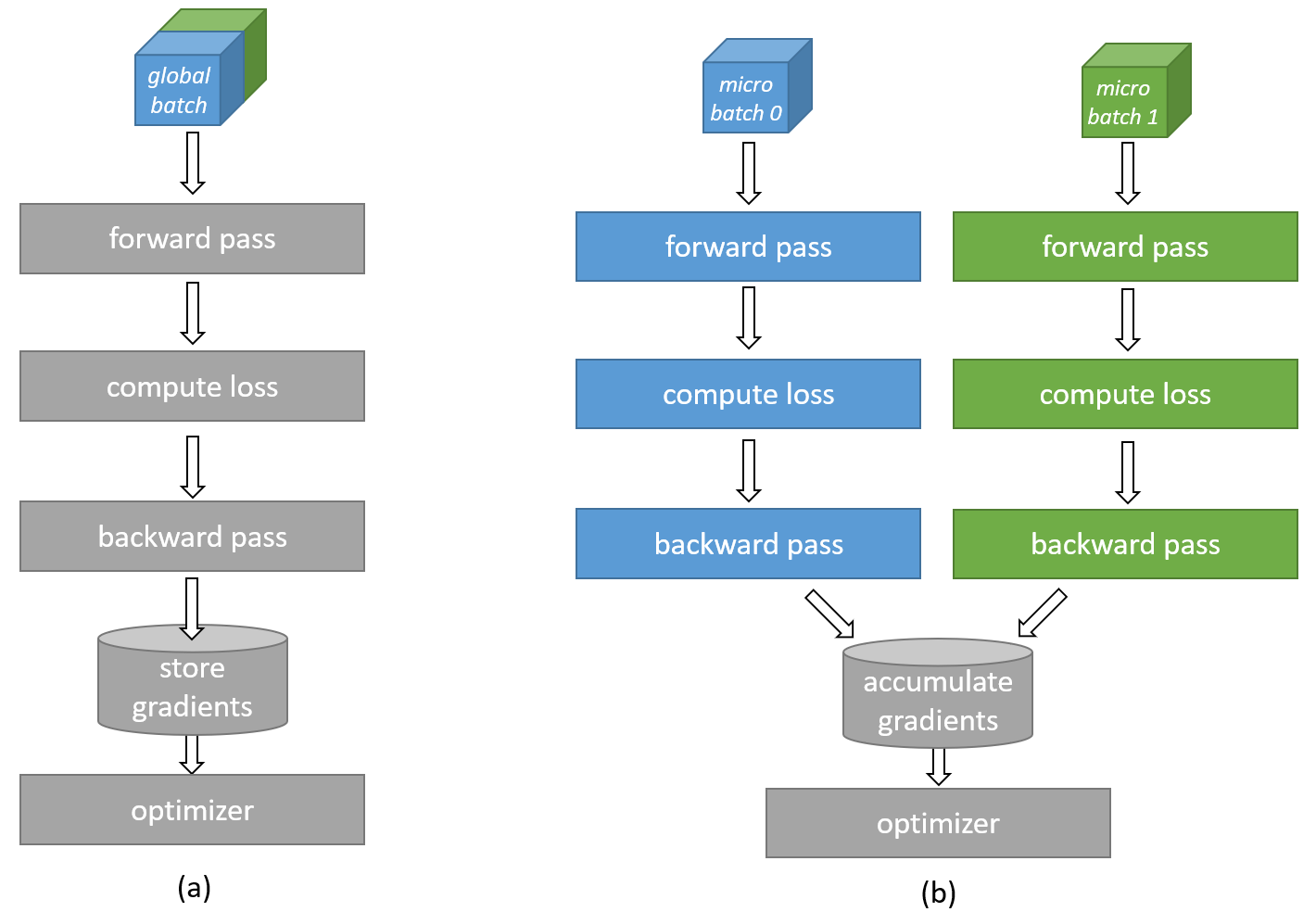
- The
batch_sizeisn’t divisible bynum_csx - The per-system batch size isn’t divisible by the
micro_batch_size
micro_batch_size parameter in the YAML config file.
Key Parameters
Some of these paramters are derived by the system.
num_csx
num_csx
(integer value) Specifies the number of Cerebras CS-X systems (e.g. CS-2s, CS-3s, etc) used for the model training run.
batch_size
batch_size
(integer value) Specifies the global batch size (GBS) of the model before the model is split along the batch dimension across
num_csx systems or into micro batches. This parameter must be larger than num_csx.per-system batch size
per-system batch size
This term is defined implicitly as
Ceil(⌈batch_size / num_csx⌉) and represents the size of the batch used on each Cerebras system. This is calculated internally by the tool and no action is required.micro_batch_size
micro_batch_size
Controls the MBS that will be used on each Cerebras system. Choose from:
NumMicroBatches
NumMicroBatches
Implicitly defined as:
NumMicroBatches = Ceil(per-system batch size / micro_batch_size)This value helps determine which micro_batch_size settings are valid. Since the smallest allowed MBS is 1, the maximum number of microbatches equals the per-system batch size. So, the valid range for NumMicroBatches is:{1, 2, ..., per-system batch size}To find all valid micro_batch_size values, divide the per-system batch size by each number in this range and take the ceiling of the result. The resulting set of values are the supported MBS options.If your specified MBS is not in the supported MBS options set the Cerebras software stack will issue a warning message and will automatically override the given MBS with the closest supported value from the set.Limitations
- Microbatching has been thoroughly tested mainly with transformer models. The technique is not compatible with models that incorporate batch normalization or layers that execute non-linear computations across batches.
- The functionality of Automatic Batch Exploration is confined to transformer models. Attempting to apply it to vision networks, such as CNNs, will result in a runtime error.
-
To circumvent extended compile times, it’s advisable to directly assign a known effective value to the
micro_batch_sizeparameter instead of leaving it undefined. -
Enabling Automatic Batch Exploration by setting
micro_batch_sizeto “explore” initiates an exhaustive search, potentially extending over several hours. However, the typical compile time for most GPT models is expected to be around one hour.