Overview
This tutorial introduces you to Cerebras essentials, including data preprocessing, training scripts, configuration files, and checkpoint conversion tools. You’ll learn these concepts by pretraining Meta’s Llama 3 8B on 40,000 lines of Shakespeare. In this quickstart, you will:- Set up your environment
- Preprocess a small dataset
- Pretrain and evaluate a model
- Convert your model checkpoint for Hugging Face
In this tutorial, you will train your model for a short while on a small dataset. A high quality model requires a longer training run, as well as a much larger dataset.
Prerequisites
To begin this guide, you must have:- Cerebras system access. If you don’t have access, contact Cerebras Support.
- Completed setup and installation.
Workflow
Create Model Directory & Copy Configs
First, save the working directory to an environment variable:Then, create a dedicated folder to store assets (like data and model configs) and generated files (such as processed datasets, checkpoints, and logs):Next, copy the sample configs into your folder. These include model configs, evaluation configs, and data configs.
We use
cp here to copy configs specifically designed for this tutorial. For general use with Model Zoo models, we recommend using cszoo config pull. See the CLI command reference for details.Inspect Configs
Before moving on, inspect the configuration files you just copied to confirm that the parameters are set as expected.
Model Config
Model Config
To view the model config, run:You should see the following content in your terminal:
Evaluation Config
Evaluation Config
To view the evaluation config, run:You should see the following content in your terminal:
Data Config
Data Config
To view the data config, run:You should see the following content in your terminal:
Preprocess Data
Use your data configs to preprocess your “train” and “validation” datasets:You should then see your preprocessed data in If you are interested, you can read more about the various parameters and pre-built utilities for preprocessing common data formats. You can also follow end-to-end tutorials for various use cases such as instruction fine-tuning and extending context lengths using position interpolation.
pretraining_tutorial/train_data/ and pretraining_tutorial/valid_data/ (see the output_dir parameter in your data configs).An example of a “train” dataset looks as follows:Inspect Preprocessed Data
Inspect Preprocessed Data
Once you’ve preprocessed your data, you can visualize the outcome:In your terminal, you will see a url like 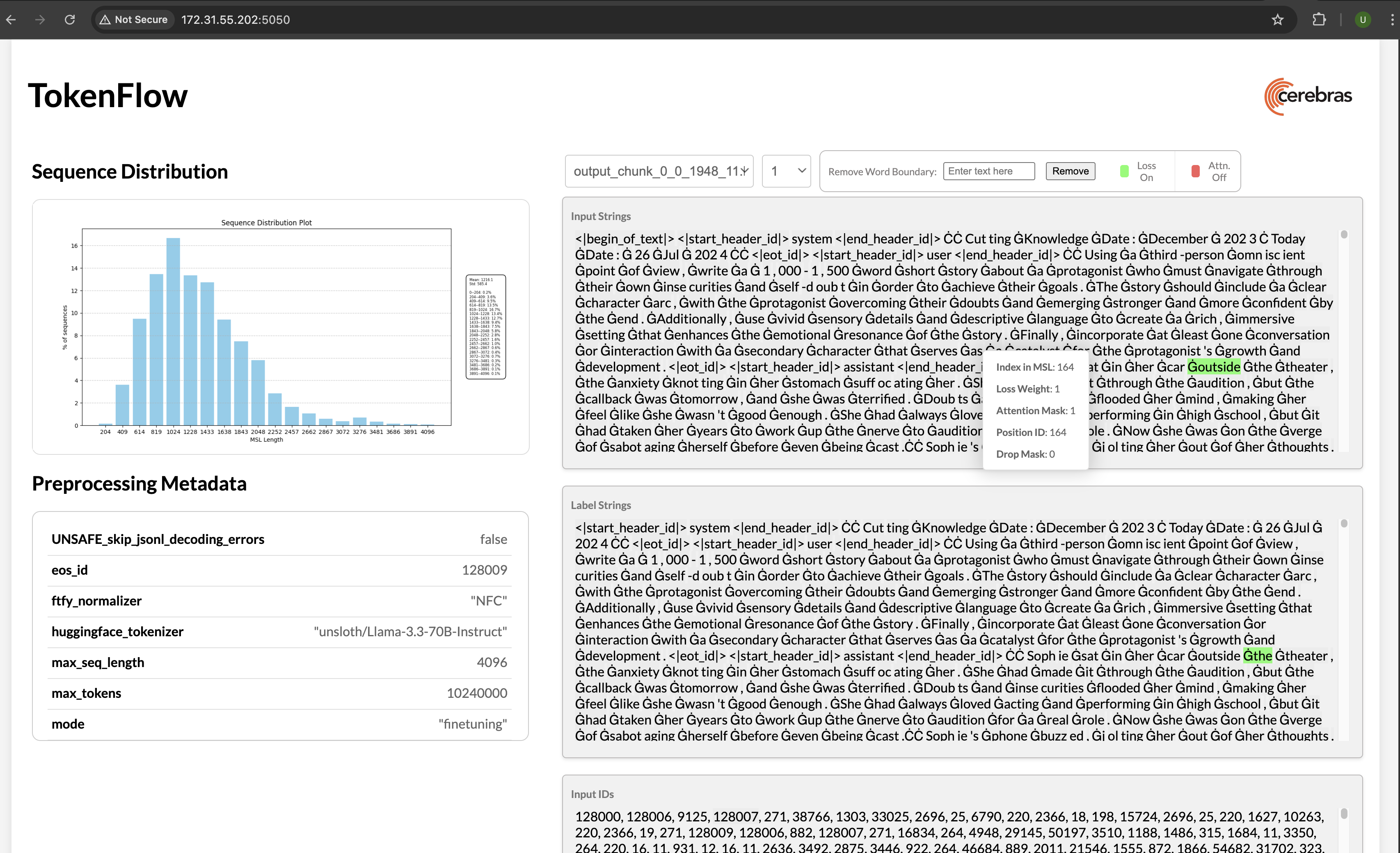
http://172.31.48.239:5000. Copy and paste this into your browser to launch TokenFlow, a tool for interactively visualizing whether loss and attention masks were applied correctly:Train and Evaluate Model
Update Now you’re ready to launch training. Use the cszoo fit command to submit a job, passing in your updated model config. This command automatically uses the locations and packages defined in your config. Click here for more information.You should then see something like this in your terminal:Once training is complete, you will find several artifacts in the
train_dataloader.data_dir and val_dataloader.data_dir in your model config to use the absolute paths of your preprocessed data:pretraining_tutorial/model folder (see the model_dir parameter in your model config). These include:- Checkpoints
- TensorBoard event files
- Run logs
- A copy of the model config
Inspect Training Logs
Monitor your training during the run or visualize TensorBoard event files afterwards:Port Model to Hugging Face
Once you train (and evaluate) your model, you can port it to Hugging Face to generate outputs:This will create both Hugging Face config files and a converted checkpoint under
pretraining_tutorial/to_hf.As a reminder, in this quickstart, you did not train your model for very long. A high quality model requires a longer training run, as well as a much larger dataset.
Conclusion
Congratulations! In this tutorial, you followed an end-to-end workflow to pretrain a model on a Cerebras system and learn about essential tools and scripts. As part of this, your learned how to:- Setup your environment
- Preprocess a small dataset
- Pretrain and evaluate a model
- Port your model to Hugging Face
What’s Next?
- Learn how to fine-tune your first model
- Learn more about data preprocessing
- Learn more about the Cerebras Model Zoo and the different models we support