What is a Semantic Region?
To write effective read hooks, you first need to understand semantic regions. A semantic region is a section of data that shares a common meaning. This concept is particularly important for instruction-following datasets where different parts of the input serve different purposes. For example, in a dialogue dataset, user questions and assistant responses are distinct semantic regions that need different treatment during training. Traditional approaches often use rigid, hard-coded masking for these sections, but semantic regions provide more flexibility.Why Use Semantic Regions?
Let’s consider the user and assistant sections of a dialogue as two special cases of a semantic region. The user section shows the model an example question, which is distinct from the assistant response that demonstrates the desired output of the model. For pedagogical purposes, we introduce a simple representation to visualize semantic regions. Below, the tuple contains(text, loss_mask_value):
- A medical passage
- A related question
- An answer
- Combine the passage and question into a single “user” region
- Lose the ability to learn from the medical passage during training
We currently do not offer the ability to divide inputs into different semantic regions in
pretraining mode. We offer this capability in finetuning mode, for both text and multi-modal datasets.Semantic Data Arrays
We also introduce a data specification for our processing pipeline, called the semantic data array. Input data can come in a variety of formats, but we require a standard format to correctly parse it into semantic regions so that we can apply the corresponding attributes such as loss weight.type field controls behavior for chat templates (more details here), and can take values of "system", "prompt", "completion", "user", "assistant". The difference between prompt/completion and user/asssistant is whether we apply a chat-template: prompt/completion does not apply the template, and user/assistant does apply the chat template.
The content field is a list of dictionaries, where the key is the name of the semantic region, and the value is the content of the semantic. Currently, the image semantic region is special and the content would have to be a string that represents the path to the image. Other regions names besides image will be interpreted as text.
The semantic_loss_weight and semantic_{drop/attention}_mask are optional, and have default values according to the type field. If specified, they should be a list that has the same number of entries as the content list.
By default, completion and assistant are not loss-masked, i.e. have semantic_loss_weight = 1. The system, prompt, and user types have default of semantic_loss_weight = 0.
All types have default of semantic_attention_mask = 1, i.e. they have attention paid to them.
All types also have defaults of semantic_drop_mask = False, which means they are not dropped. The popular LLaVA model dropped the text from their prompts in one phase of training, so we introduced this feature to support the ability to drop arbitrary semantic regions according to a desired scheme (more details here).
Now let us represent some of the pedagogical examples from above into real semantic data arrays:
When creating custom semantic regions, ensure there is a leading space at the start of each region (except the first) to prevent the merging of words from neighboring regions.
Read Hooks to Organize Semantic Data Arrays
We use read hooks to convert from different input formats to our semantic data array. Pre-built hooks are provided for standard input formats and masking schemes, but the hooks also allow you to write code to transform arbitrary inputs into any valid configuration of the semantic data array.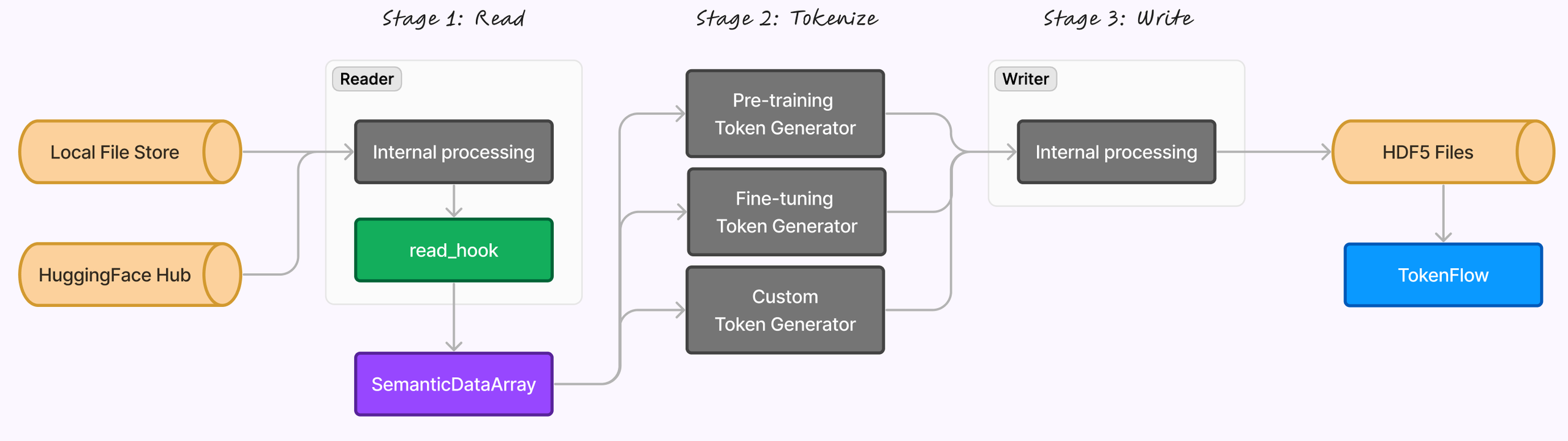
True for the text region of “prompt,” indicating that this text portion will be dropped from the dataset and not tokenized. The semantic attention mask determines which regions contribute to the final attention mask passed to the model. A loss weight of 0 for a region means that the label tokens corresponding to that region will not be included in the loss calculation.
The value of the semantic loss weight should be either 0 or 1.
Custom Read Hook Examples
This section describes examples of custom read hooks for processing data on Cerebras Systems. The return data fields are:type
Indicates the role in the conversation. Possible values are system, user, assistant, prompt, or completion.
content
A list of dictionaries representing parts of the conversation turn. Each dictionary can contain:
- text: A segment of text.
- image: The path to an image (if applicable).
Ultra Chat Common Words Mask Hook
This hook masks selected words in the sequence and was written for Ultrachat data. The link to the dataset is here. The hook implementation can be found here.Obelics Hook
Processes obelics dataset examples into a semantic data array format. Requires keys for image and text data. The dataset link and description can be found here. The hooks implementation can be found here.Llama3.1 Chat Template Formatted Data Hook
Processes a multi turn conversation dataset on which chat template of the tokenizermeta-llama/Meta-Llama-3-8B-Instruct has already been applied, into a semantic data array format. Requires keys for image and text data. The dataset link and description for a sample dataset can be found here. The hooks implementation can be found here.
Important Considerations
-
Handling keys to read data: The
read_hook_kwargsproperty must have data keys with the suffix_keyto segregate these from other parameters forread_hook_kwargs. These keys will be exclusively used to read data from the input while other parameters which are not data keys will be used to create semantic data array from the read hooks. - Space Handling: When combining custom regions, the data processor does not add any spaces or separators between the regions. Space handling must be managed within the read hooks. When creating custom semantic regions, ensure there is a leading space at the start of each region (except the first) to prevent the merging of words from neighboring regions.
- Multimodal Datasets: When working with multimodal datasets, if images are provided as URLs, the hooks should download the images and generate image paths to be used by the multimodal models.
-
Separator Handling With Prompt Completion Read Hook: The token generator adds a separator token between
promptandcompletionsemantic regions. The tokenizer’ssep_tokenattribute is used as a separator token if present; else we use<|sep|>.