Before You Begin
Before you can pre-train or fine-tune your model, preprocess your text-only or multimodal data into HDF5 format for the Cerebras platform. You will:- Set up your data directory
- Prepare your config file
- Run the preprocessing script
- Visualize the preprocessed data
-
.jsonl,.json.gz,.jsonl.zst,.jsonl.zst.tar -
.parquet -
.txt -
.fasta
Set Up Your Data Directory
Place your raw data in a directory. If processing multimodal data, set up an image directory as well. You’ll need to supply these paths in your config file. If you’re using a HuggingFace dataset, note the name of the dataset. Learn more about using HuggingFace data here.Prepare Your Config File
Your config file contains three sections:setup, processing, and dataset.
Each section is broken down below with examples for different data types.
Setup
The setup section is where you set the path to your data, the mode (pre-training or fine-tuning), and other key flags. Use the tabs to see examples for different data types:Processing
The processing section is where you define which tokenizer and read hook you want to use.Dataset
The dataset section is where you can set additional token generator parameters.Run the Preprocessing Script
Run the following command with the path to your config file:python preprocess_data.py --config /path/to/configuration/file
Visualize Your Data
This tool visualizes preprocessed data efficiently and in an organized fashion, allowing for easy debugging and error-catching in the output data. You can supply other arguments (listed below) if needed. Run the following command:python launch_tokenflow.py --output_dir <directory/of/file(s)>
In your terminal, you will see a url like http://172.31.48.239:5000. Copy and paste this into your browser to launch TokenFlow, a tool for interactively visualizing whether loss and attention masks were applied correctly:
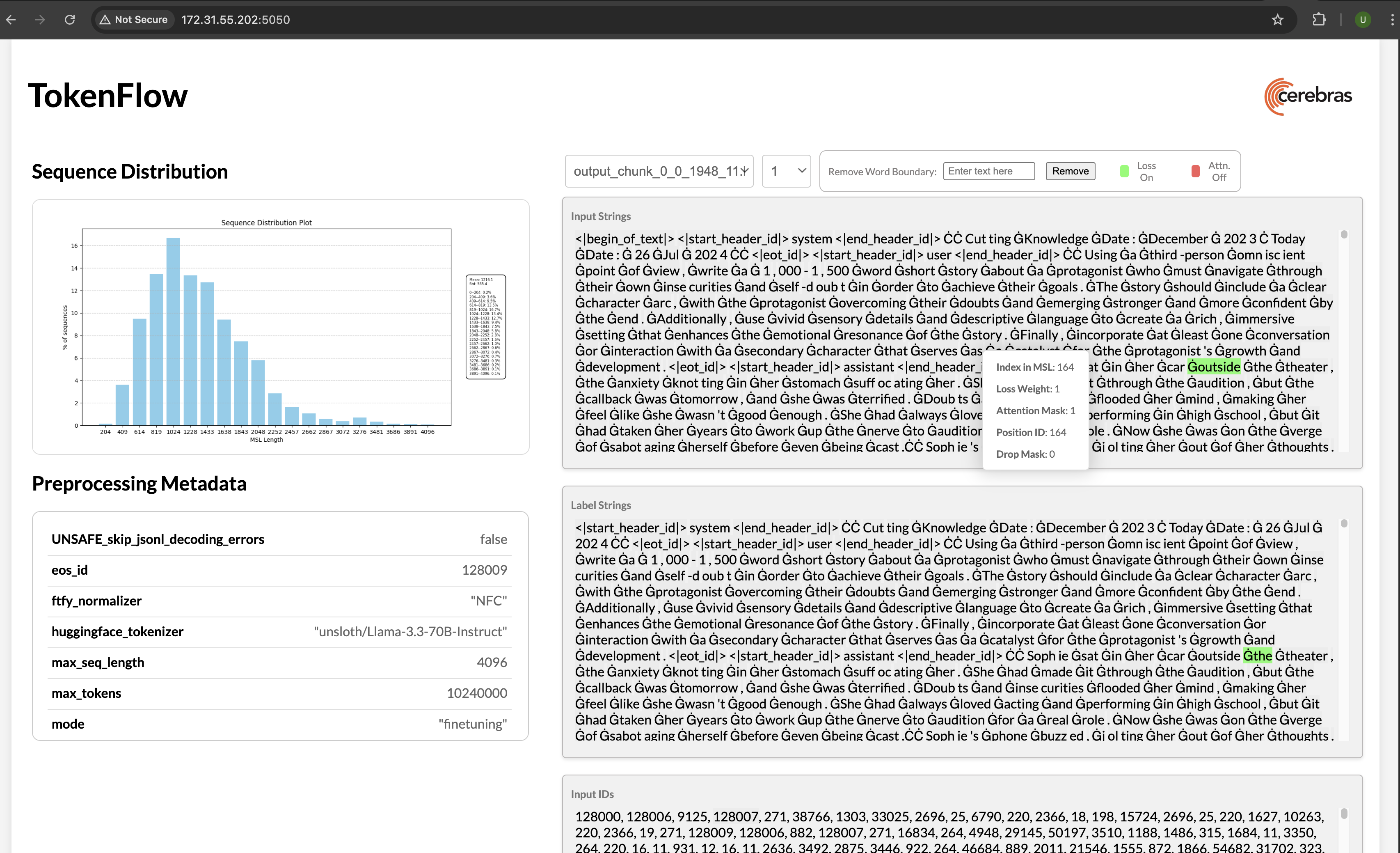
Arguments
Arguments
-
output_dir: Contains the file(s) you can view in the GUI. [Required] -
data_params: Location of the data_params.json file for the preprocessed dataset. [Optional] -
port: Use this to specify a different port for the flask server. [Optional, default=5000]
Output
There are 4 sections in the visualization output.input_strings and label_strings are converted tokens from input_ids and labels respectively. The tokens in the string sections are highlighted in green when the loss weight is greater than zero for that specific token. Similarly, the tokens are highlighted in red when their attention mask is set to zero. For multimodal datasets, hovering over the image pad tokens also displays the corresponding image in the popup window.